Image Pipeline¶
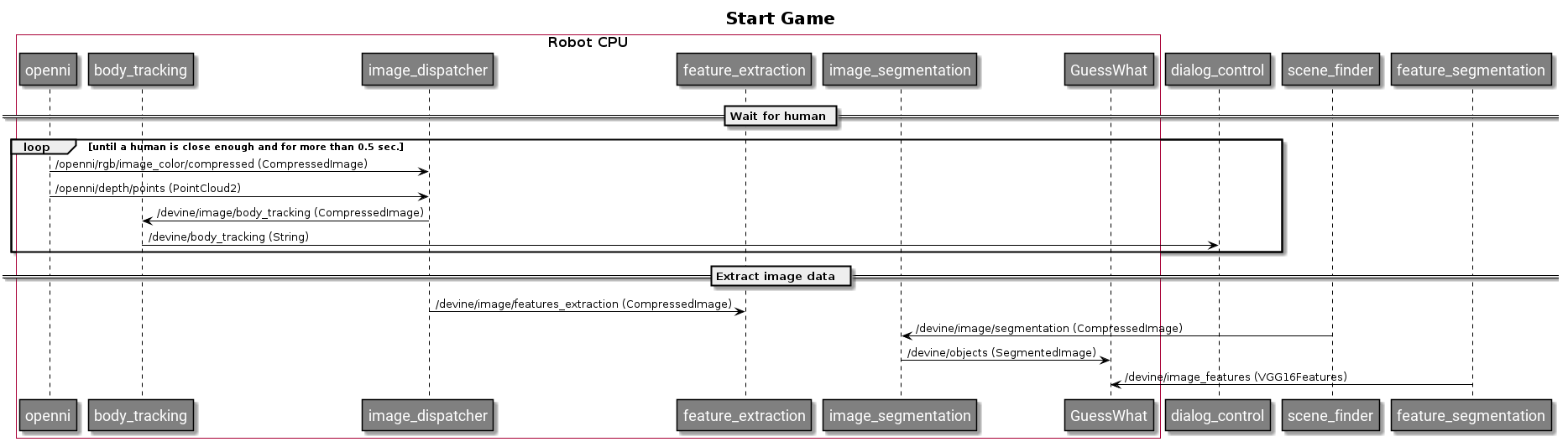
Being able to interface with GuessWhat?! and users requires taking inputs from the robot’s Kinect 360 and processing them accordingly. The first link in the chain is the image dispatcher, which takes compressed images, validates that they are not blurred, and based on the game state, sends them onto the next node in the chain.
The next node to recieve the image, temporally, is the body tracking node. Using OpenPose we try to determine if a person is within range to begin a game. If it is the case, after the scene’s picture is taken, the image is sent to the segmentation and feature extration nodes.
Interfacing with GuessWhat?! requires extracting: a list of all objects, bounding boxes around them and a feature vector (FC8 of a VGG16). Respectively the segmentatation and feature nodes are responsible for this.
Below is a UML showing the sequence of interactions between the different modules.
Additional Information¶
Specifics for each node can be found at the following links: